CS50-week 5 tutorial (data structures, singly-linked lists, hash tables, tries)
1-Nov-2021
Data Structures
Arrays
-insertion — slow: you need to delete and add the whole array(O(n)
-deletion — slow: you need to shift the position after deletion O(n)
-search(lookup): — fast: you can do random access, constant time O(constant)
-sorting — easy to sort c, the memory is stored contiguously
-size occupied in memory — relatively small (no need extra memory for pointer)
-Flexibility in size — least, size-fixed
Linked Lists
-insertion — fast: you could choose where to insert but the steps would increase O(1)
-deletion — fast: you could even choose which one to delete O(1)
-search(lookup) — slow: linear search is required
-sorting — slow: you need to do sorting one by one changing the pointer
-size occupied in memory — doubled of array, but still small comparing with other structures
-flexibility in size —high flexibility
Hash tables
new words learnt — probing : means you purely uses array??
“A hash table probe operation is used to retrieve rows from a temporary hash table based upon a probe lookup operation”//
chaining : means part of them linked list is used
“Chaining is a technique used for avoiding collisions in hash tables”
http://alrightchiu.github.io/SecondRound/hash-tableintrojian-jie.html
-insertion — relatively fast, two-step, into array(bucket)(hash → produce the array number for the word ) then into the linked list
-deletion — fast, remove from the linked list ← use chaining (take more time)// array( once you find the hash data and without collision)(once you found the data)
-search(lookup) — relatively faster than linked listed but slower than arrays, the arrays in the beginning helps a lot as you split the elements throughout arrays
-sorting — depends on the details on the arrays(bucket) (XXXXX)
-sorting is instead not ideal in hash table → array is better
-size occupied in memory — larger/ there might be unoccupied ← depends on the size of data storing (bigger than linked list but smaller than tries)
-flexibility in size — not super high(array is evolved)
Tries
-insertion — easy, you just add the pointer accordingly , once the malloc and null pointers are done before head O(constant)
-deletion — a bit time consuming,, you need to delete the linked node
easy in tutorial, you just need to free the node accordingly, but it’s that you need to free couple of nodes comparing with linked list and hash table?
-search — could be linear, depend on the data you are looking at (not on the total data size so it is constant of Big O)
-sorting — already sorted when you are doing
-size in memory — the largest occupation among the taught ones
-flexibility — high flexibility
Singly-linked list
array: collections of data in same data type ( you need to declare the data type in the beginning) ← easy for looking up information but hard to manipulate data (inserting, deleting, except sorting) // low flexibility in resizing
data structure: group different data type into a box (while array is collecting a group of data information but not only format, array is more like collection of boxes)
linked list, using arrays and pointers(nodes) to avoid waste of memory
Node: data type + pointer to another node
A linked node → chain

1. create not existed linked list
2. Search a certain element
3. Insert new node
4. delete single node
5. delete whole list
Create linked list
1. you need to create new node first
2. you need a pointer pointing to the first node
eg sllnode* create(VALUE val);
I thought would be doing it like what was done in binary tree (finish one node let the list pointer point at it, but instead , pointer with function is a good choice with a large amount of data)
what should the function include:
1. create malloc for node
1.5 confirm that there are enough spaces for malloc
2. assign information for the data (initializing value field)
2.5 initializing next field
3. point pointer to the next data
Search through the list
*** the first element of the list should be always keep track on***
bool find(sllnode* head, VALUE val);
1. create traveller pointer (pointing at the first one and move that one)
(no need to malloc for trav →the node already exist)
2. run the pointer through the first node
3. check if value in the node matches with the traveller pointer value
4. no, go to the next node and repeat checking, until was found or return
5. yes, return


Insertion
sllnode* insert(sllnode* head, VALUE val);

in the head instead of the end → is it because we dont want to waste time going through the whole list before insertion?// if put it in the head, the insertion would be easier O(n)//O(constant)

Steps for insertion
1. malloc for the new node
2. put value in new node
3. the next* in new node point to 15 first (new->next = list)
4. list point to new (list = new)
Delete entire list
void destroy(sllnode* head);
1. reached a null pointer, stop(base case)
2.Delete rest of the list (recursive) destroy(list->pointer)
3. Free the current node


首先要明白的是, 原本的function會是 — destroy(*list → next)←組成recursive function
- destroy(list (value 12) →next) 第一個放入Input的會是value 12 的node。根據function的指令, 當node中的pointer不是指向NULL, 就要把它的Next pointer放入function中繼續。 由於function中的function未完結, 要先把裏面的function reveal出來先完成, 再回來。
當下面完成即可執行命令 - destroy(list(value 15) →next)
node value 15 不是指向NULL, 所以要繼續放下一個pointer as list落去
當下面完成即可執行命令 - destroy (list(value 9) →next)
當下面完成即可執行命令 - destroy (list(value 13 →next)
當下面完成即可執行命令 - destroy( list(value 10 →next)
由於這個node是指向NULL, 所以可以執行命令
如果錯了, 會有memory leak ( memory shown in used in heap← wasted)
Delete Single element from the linked list
- when you found the node you would like to delete, you might unable to link the node-1 to the node+1 together, as pointer could not point backwards.
→ solved by doubled linked list
Hash Tables
Combining arrays (for search ← random access) and linked list(for insertion and deletion ← dynamism)
-insertion (tend to close to omega(1)
-deletion(tend to close to omega(1)
-search ((tend to close to omega(1)
take the advantages of the structure
~new structure to insert data into the structure so that data could have clue to say where it is stored in the structure
~:( still have disadvantage — longer time to re-order/sort the data (theata of n)
- hash function — returning a non-negative integer (hash code)
- array — storing data of the type we wish to place into the data structure
First, process your data into hash function and then you will get a hash code.
Second, you store the data into array at location of hash code.

How to search?
put the data you looking for into hash function →you will get the hash code
go to search the array position using that number

- all data stored should be hashed before stored into the array
- Deterministic — same hash code return from same piece of data
- Try to split out the hash code return (not the same hash code return all the time)
- like John and Johnathan ← if spread out would be better

- what is unsigned int?
- adding the ASCII number of the string
- return the reminder of [(sum of the string )/ the size of the array ]as the hash number
There are good hash functions as open source, so you don’t need to generate one on your own. But don’t forget to cite the source once you use them!!!!
Problem:

- data with same hash code through the hash function → collision
how to store the data? → store the data in the vacancy nearby the hash code generated → no need to search too far
using linear probing

Clustering — once there is a miss, the two adjacent cells will store data, the higher possibility that the cluster will grow // if the 11th/12th data were meant to place into the tables → keep spinning around infinitely
2. use Chaining
holding more than one pieces of information in the chain → doesn’t work in array (it has fixed amount of assigned space)
→ storing pointer pointing to next data like linked list
→Clustering is eliminated
→ insertion (big O of 1 ← simply add to the front of the linked list)
→ search (depends on the size of the linked list )

Tries
Two main data structure introduced: Array and Hash table
Array: Key = element index, you may find where the data was stored in the structure through the key
Hash table (chaining) : Key = hash code of the data, hash code was hashed by the linked list of data into the table
Can we use things simple as Bool to tell us if the value exist or not (Bool = 1 bit only)
Combine arrays and pointer in new way
Like a roadmap than simply storing data
-if you follow the map and goes to the end, the value exist
-if don’t, there is no such value stored
No collision, no two data get to the same pathway(except they are completely the same)
Inside a trie:
Path from central root node to leaf node, would be labeled with digits of year
From root to leaf, each node could have 10 pointers send out from them, one for each digit (0–9)
Example: key-value pairs: Key: 4-digit years(YYYY); Value: names of universities founded during those years
Insertion: build correct path from root to leaf (you need to build up the basic data structure before insertion)


The root node should be pointer with a pointer ← should not be used (could copy)


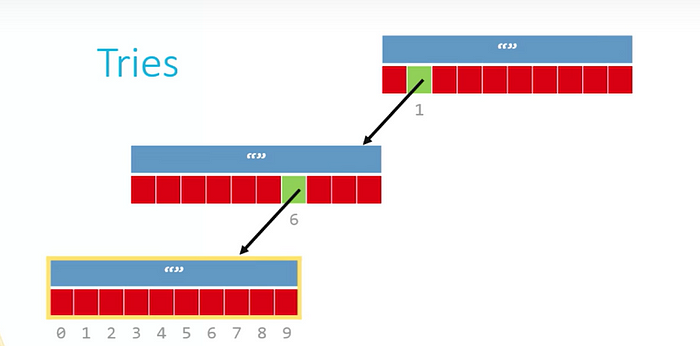


What if it is not year, like string? still use the code in array to represent the information? no need to store more char in the node to show what is the information inside?

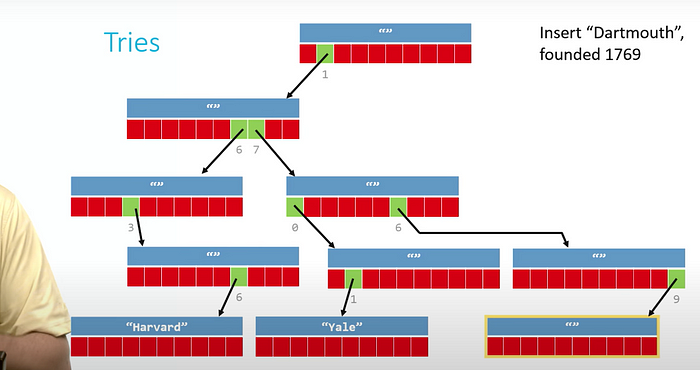
Search: use the key to go through from the root, if you reach a NULL pointer → NULL; if you reach to the end and the stored data is the same with what you are looking for→ YES
Quick insertion, deletion, lookup (constant time) ← super big memory taken